mirror of
https://github.com/AstrBotDevs/AstrBot
synced 2026-07-03 19:20:16 +08:00
Compare commits
2 Commits
codex/add-
...
fix/8853
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
e258d5ea10 | ||
|
|
05e4849e0e |
2
.github/workflows/build-docs.yml
vendored
2
.github/workflows/build-docs.yml
vendored
@@ -1,4 +1,4 @@
|
||||
name: Build and Deploy AstrBot Docs
|
||||
name: release
|
||||
|
||||
on:
|
||||
push:
|
||||
|
||||
64
.github/workflows/pr-title-check.yml
vendored
Normal file
64
.github/workflows/pr-title-check.yml
vendored
Normal file
@@ -0,0 +1,64 @@
|
||||
name: PR Title Check
|
||||
|
||||
on:
|
||||
pull_request_target:
|
||||
types: [opened, edited, reopened, synchronize]
|
||||
|
||||
jobs:
|
||||
title-format:
|
||||
if: github.repository == 'AstrBotDevs/AstrBot'
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
pull-requests: write
|
||||
issues: write
|
||||
|
||||
steps:
|
||||
- name: Validate PR title
|
||||
uses: actions/github-script@v9
|
||||
with:
|
||||
script: |
|
||||
const title = (context.payload.pull_request.title || "").trim();
|
||||
// Allow Conventional Commit style PR titles.
|
||||
// Examples:
|
||||
// feat: xxx
|
||||
// feat(scope): xxx
|
||||
// fix: xxx
|
||||
// fix(scope): xxx
|
||||
const allowedTypes = "feat|fix|docs|style|refactor|perf|test|chore|ci|build|revert";
|
||||
const pattern = new RegExp(`^(${allowedTypes})(\\([a-z0-9-]+\\))?:\\s.+$`, "i");
|
||||
const isValid = pattern.test(title);
|
||||
const isSameRepo =
|
||||
context.payload.pull_request.head.repo.full_name === context.payload.repository.full_name;
|
||||
|
||||
if (!isValid) {
|
||||
if (isSameRepo) {
|
||||
try {
|
||||
await github.rest.issues.createComment({
|
||||
owner: context.repo.owner,
|
||||
repo: context.repo.repo,
|
||||
issue_number: context.payload.pull_request.number,
|
||||
body: [
|
||||
"⚠️ PR title format check failed.",
|
||||
"Required formats:",
|
||||
"- `feat: xxx`",
|
||||
"- `feat(scope): xxx`",
|
||||
"- `fix: xxx`",
|
||||
"- `fix(scope): xxx`",
|
||||
"- `chore: xxx`",
|
||||
"",
|
||||
"Allowed prefixes:",
|
||||
"`feat`, `fix`, `docs`, `style`, `refactor`, `perf`, `test`, `chore`, `ci`, `build`, `revert`",
|
||||
"Please update your PR title and push again."
|
||||
].join("\n")
|
||||
});
|
||||
} catch (e) {
|
||||
core.warning(`Failed to post PR title comment: ${e.message}`);
|
||||
}
|
||||
} else {
|
||||
core.warning("Fork PR: comment permission is restricted; skip posting review comment.");
|
||||
}
|
||||
}
|
||||
|
||||
if (!isValid) {
|
||||
core.setFailed("Invalid PR title. Expected Conventional Commit format, e.g. feat: xxx, feat(scope): xxx, or fix: xxx.");
|
||||
}
|
||||
2
.github/workflows/release.yml
vendored
2
.github/workflows/release.yml
vendored
@@ -1,4 +1,4 @@
|
||||
name: Release AstrBot
|
||||
name: Release
|
||||
|
||||
on:
|
||||
push:
|
||||
|
||||
2
.github/workflows/sync-wiki.yml
vendored
2
.github/workflows/sync-wiki.yml
vendored
@@ -1,4 +1,4 @@
|
||||
name: Sync AstrBot Docs to GitHub Wiki
|
||||
name: sync wiki
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
import logging
|
||||
|
||||
__version__ = "4.26.0-beta.12"
|
||||
__version__ = "4.26.0-beta.11"
|
||||
logger = logging.getLogger("astrbot")
|
||||
|
||||
@@ -8,17 +8,6 @@ from filelock import FileLock, Timeout
|
||||
DASHBOARD_INITIAL_PASSWORD_ENV = "ASTRBOT_DASHBOARD_INITIAL_PASSWORD"
|
||||
|
||||
|
||||
async def check_dashboard(astrbot_root: Path) -> None:
|
||||
"""Check whether dashboard assets are available.
|
||||
|
||||
Args:
|
||||
astrbot_root: AstrBot data directory path.
|
||||
"""
|
||||
from ..utils import check_dashboard as _check_dashboard
|
||||
|
||||
await _check_dashboard(astrbot_root)
|
||||
|
||||
|
||||
def _initialize_config_from_env(astrbot_root: Path) -> None:
|
||||
if DASHBOARD_INITIAL_PASSWORD_ENV not in os.environ:
|
||||
return
|
||||
@@ -55,6 +44,8 @@ async def initialize_astrbot(astrbot_root: Path) -> None:
|
||||
|
||||
_initialize_config_from_env(astrbot_root)
|
||||
|
||||
from ..utils import check_dashboard
|
||||
|
||||
await check_dashboard(astrbot_root / "data")
|
||||
|
||||
|
||||
|
||||
@@ -85,8 +85,6 @@ from astrbot.core.tools.web_search_tools import (
|
||||
BaiduWebSearchTool,
|
||||
BochaWebSearchTool,
|
||||
BraveWebSearchTool,
|
||||
ExaGetContentsTool,
|
||||
ExaWebSearchTool,
|
||||
FirecrawlExtractWebPageTool,
|
||||
FirecrawlWebSearchTool,
|
||||
TavilyExtractWebPageTool,
|
||||
@@ -132,7 +130,6 @@ WEB_SEARCH_CITATION_TOOL_NAMES = frozenset(
|
||||
"web_search_tavily",
|
||||
"web_search_bocha",
|
||||
"web_search_brave",
|
||||
"web_search_exa",
|
||||
}
|
||||
)
|
||||
WEB_SEARCH_CITATION_PROMPT = (
|
||||
@@ -1210,9 +1207,6 @@ async def _apply_web_search_tools(
|
||||
req.func_tool.add_tool(tool_mgr.get_builtin_tool(FirecrawlExtractWebPageTool))
|
||||
elif provider == "baidu_ai_search":
|
||||
req.func_tool.add_tool(tool_mgr.get_builtin_tool(BaiduWebSearchTool))
|
||||
elif provider == "exa":
|
||||
req.func_tool.add_tool(tool_mgr.get_builtin_tool(ExaWebSearchTool))
|
||||
req.func_tool.add_tool(tool_mgr.get_builtin_tool(ExaGetContentsTool))
|
||||
|
||||
|
||||
def _apply_web_search_citation_prompt(
|
||||
|
||||
@@ -115,7 +115,6 @@ DEFAULT_CONFIG = {
|
||||
"websearch_brave_key": [],
|
||||
"websearch_baidu_app_builder_key": "",
|
||||
"websearch_firecrawl_key": [],
|
||||
"websearch_exa_key": [],
|
||||
"web_search_link": False,
|
||||
"display_reasoning_text": False,
|
||||
"identifier": False,
|
||||
@@ -3296,7 +3295,6 @@ CONFIG_METADATA_3 = {
|
||||
"bocha",
|
||||
"brave",
|
||||
"firecrawl",
|
||||
"exa",
|
||||
],
|
||||
"condition": {
|
||||
"provider_settings.web_search": True,
|
||||
@@ -3351,16 +3349,6 @@ CONFIG_METADATA_3 = {
|
||||
"provider_settings.web_search": True,
|
||||
},
|
||||
},
|
||||
"provider_settings.websearch_exa_key": {
|
||||
"description": "Exa API Key",
|
||||
"type": "list",
|
||||
"items": {"type": "string"},
|
||||
"hint": "可添加多个 Key 进行轮询。Get a key at https://dashboard.exa.ai",
|
||||
"condition": {
|
||||
"provider_settings.websearch_provider": "exa",
|
||||
"provider_settings.web_search": True,
|
||||
},
|
||||
},
|
||||
"provider_settings.web_search_link": {
|
||||
"description": "显示来源引用",
|
||||
"type": "bool",
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
import asyncio
|
||||
import json
|
||||
import re
|
||||
from collections.abc import Awaitable, Callable
|
||||
from datetime import datetime, timezone
|
||||
from typing import TYPE_CHECKING, Any
|
||||
@@ -24,70 +23,6 @@ if TYPE_CHECKING:
|
||||
from astrbot.core.star.context import Context
|
||||
|
||||
|
||||
_CRONTAB_WEEKDAY_NAMES = ("sun", "mon", "tue", "wed", "thu", "fri", "sat")
|
||||
_CRONTAB_WEEKDAY_PATTERN = re.compile(r"^(?:(\*)|(\d+)(?:-(\d+))?)(?:/(\d+))?$")
|
||||
|
||||
|
||||
def _normalize_crontab_day_of_week(day_of_week: str) -> str:
|
||||
"""Normalize standard crontab weekdays for APScheduler.
|
||||
|
||||
APScheduler treats numeric weekdays as Monday=0, while standard crontab and
|
||||
AstrBot's WebUI use Sunday=0/7. Numeric weekday fields are expanded to
|
||||
weekday names so the scheduled day remains unambiguous.
|
||||
|
||||
Args:
|
||||
day_of_week: The day-of-week field from a five-part crontab expression.
|
||||
|
||||
Returns:
|
||||
A day-of-week field compatible with APScheduler.
|
||||
|
||||
Raises:
|
||||
ValueError: If a numeric weekday value or step is outside the supported
|
||||
crontab range.
|
||||
"""
|
||||
normalized_parts: list[str] = []
|
||||
for raw_part in day_of_week.split(","):
|
||||
part = raw_part.strip().lower()
|
||||
match = _CRONTAB_WEEKDAY_PATTERN.fullmatch(part)
|
||||
if not match:
|
||||
normalized_parts.append(part)
|
||||
continue
|
||||
|
||||
wildcard, start_text, end_text, step_text = match.groups()
|
||||
step = int(step_text or "1")
|
||||
if step < 1:
|
||||
raise ValueError("day_of_week step must be greater than 0")
|
||||
|
||||
if wildcard:
|
||||
if step == 1:
|
||||
normalized_parts.append("*")
|
||||
continue
|
||||
values = range(0, 7, step)
|
||||
else:
|
||||
start = int(start_text)
|
||||
end = int(end_text) if end_text is not None else None
|
||||
if start < 0 or start > 7 or (end is not None and (end < 0 or end > 7)):
|
||||
raise ValueError("day_of_week values must be between 0 and 7")
|
||||
if end is not None and start > end:
|
||||
raise ValueError("day_of_week range start must not exceed end")
|
||||
if end is None:
|
||||
end = 7 if step_text else start
|
||||
values = range(start, end + 1, step)
|
||||
|
||||
weekdays: list[int] = []
|
||||
for value in values:
|
||||
weekday = 0 if value == 7 else value
|
||||
if weekday not in weekdays:
|
||||
weekdays.append(weekday)
|
||||
|
||||
if len(weekdays) == 7:
|
||||
normalized_parts.append("*")
|
||||
else:
|
||||
normalized_parts.extend(_CRONTAB_WEEKDAY_NAMES[value] for value in weekdays)
|
||||
|
||||
return ",".join(normalized_parts)
|
||||
|
||||
|
||||
class CronJobSchedulingError(Exception):
|
||||
"""Raised when a cron job fails to be scheduled."""
|
||||
|
||||
@@ -242,21 +177,7 @@ class CronJobManager:
|
||||
run_at = run_at.replace(tzinfo=tzinfo)
|
||||
trigger = DateTrigger(run_date=run_at, timezone=tzinfo)
|
||||
else:
|
||||
if not job.cron_expression:
|
||||
raise ValueError("recurring job missing cron_expression")
|
||||
minute, hour, day, month, day_of_week = job.cron_expression.split()
|
||||
normalized_cron_expression = " ".join(
|
||||
[
|
||||
minute,
|
||||
hour,
|
||||
day,
|
||||
month,
|
||||
_normalize_crontab_day_of_week(day_of_week),
|
||||
]
|
||||
)
|
||||
trigger = CronTrigger.from_crontab(
|
||||
normalized_cron_expression, timezone=tzinfo
|
||||
)
|
||||
trigger = CronTrigger.from_crontab(job.cron_expression, timezone=tzinfo)
|
||||
self.scheduler.add_job(
|
||||
self._run_job,
|
||||
id=job.job_id,
|
||||
|
||||
@@ -21,8 +21,6 @@ WEB_SEARCH_TOOL_NAMES = [
|
||||
"web_search_brave",
|
||||
"web_search_firecrawl",
|
||||
"firecrawl_extract_web_page",
|
||||
"web_search_exa",
|
||||
"exa_get_contents",
|
||||
]
|
||||
_TAVILY_WEB_SEARCH_TOOL_CONFIG = {
|
||||
"provider_settings.web_search": True,
|
||||
@@ -44,10 +42,6 @@ _BAIDU_WEB_SEARCH_TOOL_CONFIG = {
|
||||
"provider_settings.web_search": True,
|
||||
"provider_settings.websearch_provider": "baidu_ai_search",
|
||||
}
|
||||
_EXA_WEB_SEARCH_TOOL_CONFIG = {
|
||||
"provider_settings.web_search": True,
|
||||
"provider_settings.websearch_provider": "exa",
|
||||
}
|
||||
|
||||
|
||||
@std_dataclass
|
||||
@@ -82,7 +76,6 @@ _TAVILY_KEY_ROTATOR = _KeyRotator("websearch_tavily_key", "Tavily")
|
||||
_BOCHA_KEY_ROTATOR = _KeyRotator("websearch_bocha_key", "BoCha")
|
||||
_BRAVE_KEY_ROTATOR = _KeyRotator("websearch_brave_key", "Brave")
|
||||
_FIRECRAWL_KEY_ROTATOR = _KeyRotator("websearch_firecrawl_key", "Firecrawl")
|
||||
_EXA_KEY_ROTATOR = _KeyRotator("websearch_exa_key", "Exa")
|
||||
|
||||
|
||||
def normalize_legacy_web_search_config(cfg) -> None:
|
||||
@@ -106,7 +99,6 @@ def normalize_legacy_web_search_config(cfg) -> None:
|
||||
"websearch_bocha_key",
|
||||
"websearch_brave_key",
|
||||
"websearch_firecrawl_key",
|
||||
"websearch_exa_key",
|
||||
):
|
||||
value = provider_settings.get(setting_name)
|
||||
if isinstance(value, str):
|
||||
@@ -811,231 +803,10 @@ class BaiduWebSearchTool(FunctionTool[AstrAgentContext]):
|
||||
return _search_result_payload(results)
|
||||
|
||||
|
||||
async def _exa_search(
|
||||
provider_settings: dict,
|
||||
payload: dict,
|
||||
) -> list[SearchResult]:
|
||||
"""Call the Exa /search endpoint and return normalized results."""
|
||||
exa_key = await _EXA_KEY_ROTATOR.get(provider_settings)
|
||||
headers = {
|
||||
"x-api-key": exa_key,
|
||||
"Content-Type": "application/json",
|
||||
}
|
||||
async with aiohttp.ClientSession(trust_env=True) as session:
|
||||
async with session.post(
|
||||
"https://api.exa.ai/search",
|
||||
json=payload,
|
||||
headers=headers,
|
||||
) as response:
|
||||
if response.status != 200:
|
||||
reason = await response.text()
|
||||
raise Exception(
|
||||
f"Exa web search failed: {reason}, status: {response.status}",
|
||||
)
|
||||
data = await response.json()
|
||||
return [
|
||||
SearchResult(
|
||||
title=item.get("title", ""),
|
||||
url=item.get("url", ""),
|
||||
snippet=(
|
||||
item.get("text")
|
||||
or (item.get("highlights") or [""])[0]
|
||||
or item.get("summary", "")
|
||||
),
|
||||
)
|
||||
for item in data.get("results", [])
|
||||
if item.get("url")
|
||||
]
|
||||
|
||||
|
||||
async def _exa_get_contents(
|
||||
provider_settings: dict,
|
||||
payload: dict,
|
||||
) -> list[dict]:
|
||||
"""Call the Exa /contents endpoint and return raw result dicts."""
|
||||
exa_key = await _EXA_KEY_ROTATOR.get(provider_settings)
|
||||
headers = {
|
||||
"x-api-key": exa_key,
|
||||
"Content-Type": "application/json",
|
||||
}
|
||||
async with aiohttp.ClientSession(trust_env=True) as session:
|
||||
async with session.post(
|
||||
"https://api.exa.ai/contents",
|
||||
json=payload,
|
||||
headers=headers,
|
||||
) as response:
|
||||
if response.status != 200:
|
||||
reason = await response.text()
|
||||
raise Exception(
|
||||
f"Exa get contents failed: {reason}, status: {response.status}",
|
||||
)
|
||||
data = await response.json()
|
||||
return data.get("results", [])
|
||||
|
||||
|
||||
@builtin_tool(config=_EXA_WEB_SEARCH_TOOL_CONFIG)
|
||||
@pydantic_dataclass
|
||||
class ExaWebSearchTool(FunctionTool[AstrAgentContext]):
|
||||
"""Web search tool powered by the Exa Search API."""
|
||||
|
||||
name: str = "web_search_exa"
|
||||
description: str = (
|
||||
"A web search tool powered by Exa, an AI-native search engine. "
|
||||
"Supports keyword and semantic search with domain, date, and category filters."
|
||||
)
|
||||
parameters: dict = Field(
|
||||
default_factory=lambda: {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"query": {"type": "string", "description": "Required. Search query."},
|
||||
"num_results": {
|
||||
"type": "integer",
|
||||
"description": "Optional. Number of results to return. Default is 10.",
|
||||
},
|
||||
"type": {
|
||||
"type": "string",
|
||||
"description": (
|
||||
'Optional. Search type. One of "auto", "keyword", "neural". '
|
||||
'Default is "auto".'
|
||||
),
|
||||
},
|
||||
"category": {
|
||||
"type": "string",
|
||||
"description": (
|
||||
"Optional. Category filter. One of "
|
||||
'"company", "research paper", "news", "github", '
|
||||
'"tweet", "personal site", "pdf", "linkedin profile".'
|
||||
),
|
||||
},
|
||||
"include_domains": {
|
||||
"type": "string",
|
||||
"description": "Optional. Comma-separated domains to restrict results to.",
|
||||
},
|
||||
"exclude_domains": {
|
||||
"type": "string",
|
||||
"description": "Optional. Comma-separated domains to exclude from results.",
|
||||
},
|
||||
"start_published_date": {
|
||||
"type": "string",
|
||||
"description": "Optional. Start date filter in ISO 8601 format (e.g. 2024-01-01T00:00:00.000Z).",
|
||||
},
|
||||
"end_published_date": {
|
||||
"type": "string",
|
||||
"description": "Optional. End date filter in ISO 8601 format.",
|
||||
},
|
||||
},
|
||||
"required": ["query"],
|
||||
}
|
||||
)
|
||||
|
||||
async def call(self, context, **kwargs) -> ToolExecResult:
|
||||
_, provider_settings, _ = _get_runtime(context)
|
||||
if not provider_settings.get("websearch_exa_key", []):
|
||||
return "Error: Exa API key is not configured in AstrBot."
|
||||
|
||||
try:
|
||||
num_results = int(kwargs.get("num_results", 10))
|
||||
except (TypeError, ValueError):
|
||||
num_results = 10
|
||||
if num_results < 1:
|
||||
num_results = 1
|
||||
|
||||
search_type = kwargs.get("type", "auto")
|
||||
if search_type not in ("auto", "keyword", "neural"):
|
||||
search_type = "auto"
|
||||
|
||||
payload: dict = {
|
||||
"query": kwargs["query"],
|
||||
"numResults": num_results,
|
||||
"type": search_type,
|
||||
"contents": {"text": {"maxCharacters": 500}},
|
||||
}
|
||||
|
||||
category = kwargs.get("category", "")
|
||||
if category:
|
||||
payload["category"] = category
|
||||
|
||||
include_domains = str(kwargs.get("include_domains", "")).strip()
|
||||
if include_domains:
|
||||
payload["includeDomains"] = [
|
||||
d.strip() for d in include_domains.split(",") if d.strip()
|
||||
]
|
||||
|
||||
exclude_domains = str(kwargs.get("exclude_domains", "")).strip()
|
||||
if exclude_domains:
|
||||
payload["excludeDomains"] = [
|
||||
d.strip() for d in exclude_domains.split(",") if d.strip()
|
||||
]
|
||||
|
||||
if kwargs.get("start_published_date"):
|
||||
payload["startPublishedDate"] = kwargs["start_published_date"]
|
||||
if kwargs.get("end_published_date"):
|
||||
payload["endPublishedDate"] = kwargs["end_published_date"]
|
||||
|
||||
results = await _exa_search(provider_settings, payload)
|
||||
if not results:
|
||||
return "Error: Exa web search does not return any results."
|
||||
return _search_result_payload(results)
|
||||
|
||||
|
||||
@builtin_tool(config=_EXA_WEB_SEARCH_TOOL_CONFIG)
|
||||
@pydantic_dataclass
|
||||
class ExaGetContentsTool(FunctionTool[AstrAgentContext]):
|
||||
"""Extract full page content from URLs using the Exa Contents API."""
|
||||
|
||||
name: str = "exa_get_contents"
|
||||
description: str = "Extract the content of a web page using Exa."
|
||||
parameters: dict = Field(
|
||||
default_factory=lambda: {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"url": {
|
||||
"type": "string",
|
||||
"description": "Required. A URL to extract content from.",
|
||||
},
|
||||
"max_characters": {
|
||||
"type": "integer",
|
||||
"description": "Optional. Maximum number of characters to return. Default is 3000.",
|
||||
},
|
||||
},
|
||||
"required": ["url"],
|
||||
}
|
||||
)
|
||||
|
||||
async def call(self, context, **kwargs) -> ToolExecResult:
|
||||
_, provider_settings, _ = _get_runtime(context)
|
||||
if not provider_settings.get("websearch_exa_key", []):
|
||||
return "Error: Exa API key is not configured in AstrBot."
|
||||
|
||||
url = str(kwargs.get("url", "")).strip()
|
||||
if not url:
|
||||
return "Error: url must be a non-empty string."
|
||||
|
||||
try:
|
||||
max_characters = int(kwargs.get("max_characters", 3000))
|
||||
except (TypeError, ValueError):
|
||||
max_characters = 3000
|
||||
results = await _exa_get_contents(
|
||||
provider_settings,
|
||||
{
|
||||
"ids": [url],
|
||||
"text": {"maxCharacters": max_characters},
|
||||
},
|
||||
)
|
||||
ret_ls = []
|
||||
for result in results:
|
||||
ret_ls.append(f"URL: {result.get('url', 'No URL')}")
|
||||
ret_ls.append(f"Content: {result.get('text', 'No content')}")
|
||||
ret = "\n".join(ret_ls)
|
||||
return ret or "Error: Exa get contents does not return any results."
|
||||
|
||||
|
||||
__all__ = [
|
||||
"BaiduWebSearchTool",
|
||||
"BochaWebSearchTool",
|
||||
"BraveWebSearchTool",
|
||||
"ExaGetContentsTool",
|
||||
"ExaWebSearchTool",
|
||||
"TavilyExtractWebPageTool",
|
||||
"TavilyWebSearchTool",
|
||||
"WEB_SEARCH_TOOL_NAMES",
|
||||
|
||||
@@ -54,7 +54,6 @@ ALL_OPEN_API_SCOPES = (
|
||||
"im",
|
||||
"config",
|
||||
"chat",
|
||||
"data",
|
||||
"file",
|
||||
"plugin",
|
||||
"mcp",
|
||||
|
||||
@@ -495,9 +495,7 @@ class KnowledgeBaseService:
|
||||
|
||||
files_to_upload = []
|
||||
for file in file_list:
|
||||
file_name = Path(str(file.filename or "document").replace("\\", "/")).name
|
||||
if file_name in {"", ".", ".."}:
|
||||
file_name = "document"
|
||||
file_name = file.filename
|
||||
temp_file_path = (
|
||||
Path(get_astrbot_temp_path()) / f"kb_upload_{uuid.uuid4()}_{file_name}"
|
||||
)
|
||||
|
||||
@@ -872,10 +872,9 @@ class PluginService:
|
||||
) -> tuple[dict, str]:
|
||||
self._ensure_not_demo()
|
||||
logger.info(f"正在安装用户上传的插件 {upload_file.filename}")
|
||||
filename = str(upload_file.filename or "plugin.zip").replace("\\", "/")
|
||||
file_path = os.path.join(
|
||||
get_astrbot_temp_path(),
|
||||
f"plugin_upload_{os.path.basename(filename) or 'plugin.zip'}",
|
||||
f"plugin_upload_{upload_file.filename}",
|
||||
)
|
||||
await upload_file.save(file_path)
|
||||
try:
|
||||
|
||||
@@ -1,7 +0,0 @@
|
||||
## What's Changed
|
||||
|
||||
<!-- Review, group, and polish these entries before publishing. -->
|
||||
|
||||
- fix: 修复提供商源修改 ID 后保存被静默还原的问题 (#8915) (42ca89d6c)
|
||||
- fix: created unnecessary data dir when executing astrbot command (#8932) (39d425316)
|
||||
- fix: add sdist build artifact path to allow dashboard artifact to be included (#8933) (05148dfdd)
|
||||
@@ -9,7 +9,7 @@
|
||||
<meta name="robots" content="noindex, nofollow" />
|
||||
<link
|
||||
rel="stylesheet"
|
||||
href="https://fonts.googleapis.com/css2?family=Outfit&family=Noto+Sans:wght@100..900&display=swap"
|
||||
href="https://fonts.googleapis.com/css2?family=Outfit&family=Noto+Sans:wght@100..900&family=Noto+Sans+SC:wght@100..900&display=swap"
|
||||
/>
|
||||
<!-- VAD (Voice Activity Detection) Libraries -->
|
||||
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.22.0/dist/ort.wasm.min.js"></script>
|
||||
|
||||
@@ -86,9 +86,6 @@ export type ChatProjectRequest = {
|
||||
};
|
||||
|
||||
export type ChatRequest = {
|
||||
/**
|
||||
* Caller-declared WebChat sender/session owner. This value is used as the message sender identity and may participate in sender-ID-based command permission checks. Treat chat-scoped API keys as trusted backend credentials and map or validate usernames before accepting end-user input.
|
||||
*/
|
||||
username?: string;
|
||||
session_id?: string;
|
||||
/**
|
||||
@@ -194,7 +191,7 @@ export type ConversationRef = {
|
||||
|
||||
export type CreateApiKeyRequest = {
|
||||
name: string;
|
||||
scopes?: Array<('bot' | 'provider' | 'persona' | 'im' | 'config' | 'chat' | 'data' | 'file' | 'plugin' | 'mcp' | 'skill')>;
|
||||
scopes?: Array<('bot' | 'provider' | 'persona' | 'im' | 'config' | 'chat' | 'file' | 'plugin' | 'mcp' | 'skill')>;
|
||||
expires_at?: string;
|
||||
expires_in_days?: number;
|
||||
};
|
||||
|
||||
BIN
dashboard/src/assets/images/platform_logos/vocechat.png
Normal file
BIN
dashboard/src/assets/images/platform_logos/vocechat.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 59 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 7.9 KiB After Width: | Height: | Size: 46 KiB |
@@ -156,12 +156,6 @@ function dismiss() {
|
||||
visible.value = false;
|
||||
}
|
||||
|
||||
function reloadWithCacheBuster() {
|
||||
const url = new URL(window.location.href);
|
||||
url.searchParams.set('_r', Date.now().toString());
|
||||
window.location.replace(url.toString());
|
||||
}
|
||||
|
||||
function waitForRestart() {
|
||||
clearRestartTimer();
|
||||
let attempts = 0;
|
||||
@@ -175,7 +169,7 @@ function waitForRestart() {
|
||||
) {
|
||||
clearRestartTimer();
|
||||
sessionStorage.removeItem(UPGRADE_RECOVERY_TOKEN_KEY);
|
||||
reloadWithCacheBuster();
|
||||
window.location.reload();
|
||||
}
|
||||
} catch (_error) {
|
||||
// The backend may be temporarily unavailable during restart.
|
||||
|
||||
@@ -31,11 +31,6 @@ export default {
|
||||
}
|
||||
},
|
||||
methods: {
|
||||
reloadWithCacheBuster() {
|
||||
const url = new URL(window.location.href)
|
||||
url.searchParams.set('_r', Date.now().toString())
|
||||
window.location.replace(url.toString())
|
||||
},
|
||||
async check(initialStartTime = null) {
|
||||
this.newStartTime = -1
|
||||
this.cnt = 0
|
||||
@@ -88,7 +83,8 @@ export default {
|
||||
this.newStartTime = newStartTime
|
||||
console.log('wfr: restarted')
|
||||
this.visible = false
|
||||
this.reloadWithCacheBuster()
|
||||
// reload
|
||||
window.location.reload()
|
||||
}
|
||||
} catch (_error) {
|
||||
// backend may be unavailable during restart window
|
||||
|
||||
@@ -139,10 +139,6 @@
|
||||
},
|
||||
"web_search_link": {
|
||||
"description": "Display Source Citations"
|
||||
},
|
||||
"websearch_exa_key": {
|
||||
"description": "Exa API Key",
|
||||
"hint": "Multiple keys can be added for rotation. Get a key at https://dashboard.exa.ai"
|
||||
}
|
||||
}
|
||||
},
|
||||
@@ -1225,22 +1221,22 @@
|
||||
"hint": "Only effective for qwen3-rerank models. Recommended to write in English."
|
||||
},
|
||||
"nvidia_rerank_api_base": {
|
||||
"description": "API Base URL"
|
||||
"description": "API Base URL"
|
||||
},
|
||||
"nvidia_rerank_api_key": {
|
||||
"description": "API Key"
|
||||
"description": "API Key"
|
||||
},
|
||||
"nvidia_rerank_model": {
|
||||
"description": "Rerank Model Name",
|
||||
"hint": "Please refer to the NVIDIA Docs for the model name."
|
||||
"description": "Rerank Model Name",
|
||||
"hint": "Please refer to the NVIDIA Docs for the model name."
|
||||
},
|
||||
"nvidia_rerank_model_endpoint": {
|
||||
"description": "Custom Model Endpoint",
|
||||
"hint": "Custom URL suffix endpoint, defaults to /reranking."
|
||||
"description": "Custom Model Endpoint",
|
||||
"hint": "Custom URL suffix endpoint, defaults to /reranking."
|
||||
},
|
||||
"nvidia_rerank_truncate": {
|
||||
"description": "Text Truncation Strategy",
|
||||
"hint": "Whether to truncate the input to fit the model's maximum context length when the input text is too long."
|
||||
"description": "Text Truncation Strategy",
|
||||
"hint": "Whether to truncate the input to fit the model's maximum context length when the input text is too long."
|
||||
},
|
||||
"launch_model_if_not_running": {
|
||||
"description": "Auto-start model if not running",
|
||||
|
||||
@@ -139,10 +139,6 @@
|
||||
},
|
||||
"web_search_link": {
|
||||
"description": "Показывать ссылки на источники"
|
||||
},
|
||||
"websearch_exa_key": {
|
||||
"description": "API-ключ Exa",
|
||||
"hint": "Можно добавить несколько ключей для ротации. Получить ключ: https://dashboard.exa.ai"
|
||||
}
|
||||
}
|
||||
},
|
||||
|
||||
@@ -141,10 +141,6 @@
|
||||
},
|
||||
"web_search_link": {
|
||||
"description": "显示来源引用"
|
||||
},
|
||||
"websearch_exa_key": {
|
||||
"description": "Exa API Key",
|
||||
"hint": "可添加多个 Key 进行轮询。获取 Key: https://dashboard.exa.ai"
|
||||
}
|
||||
}
|
||||
},
|
||||
|
||||
@@ -611,13 +611,7 @@ async function fetchAstrBotStartTime() {
|
||||
|
||||
function reloadAfterUpdate() {
|
||||
stopRestartReloadTimer();
|
||||
reloadWithCacheBuster();
|
||||
}
|
||||
|
||||
function reloadWithCacheBuster() {
|
||||
const url = new URL(window.location.href);
|
||||
url.searchParams.set("_r", Date.now().toString());
|
||||
window.location.replace(url.toString());
|
||||
window.location.reload();
|
||||
}
|
||||
|
||||
function showRestartCompleted() {
|
||||
@@ -825,7 +819,7 @@ function updateDashboard() {
|
||||
updateStatus.value = res.data.message || "";
|
||||
if (res.data.status == "ok") {
|
||||
setTimeout(() => {
|
||||
reloadWithCacheBuster();
|
||||
window.location.reload();
|
||||
}, 1000);
|
||||
}
|
||||
})
|
||||
|
||||
@@ -513,7 +513,6 @@ const availableScopes = [
|
||||
{ value: 'im', label: 'im' },
|
||||
{ value: 'config', label: 'config' },
|
||||
{ value: 'chat', label: 'chat' },
|
||||
{ value: 'data', label: 'data' },
|
||||
{ value: 'file', label: 'file' },
|
||||
{ value: 'plugin', label: 'plugin' },
|
||||
{ value: 'mcp', label: 'mcp' },
|
||||
|
||||
@@ -14,11 +14,11 @@ When using a large language model that supports function calling with the web se
|
||||
|
||||
And other prompts with search intent to trigger the model to invoke the search tool.
|
||||
|
||||
AstrBot currently supports 6 web search providers: `Tavily`, `BoCha`, `Baidu AI Search`, `Brave`, `Firecrawl`, and `Exa`.
|
||||
AstrBot currently supports 5 web search providers: `Tavily`, `BoCha`, `Baidu AI Search`, `Brave`, and `Firecrawl`.
|
||||
|
||||
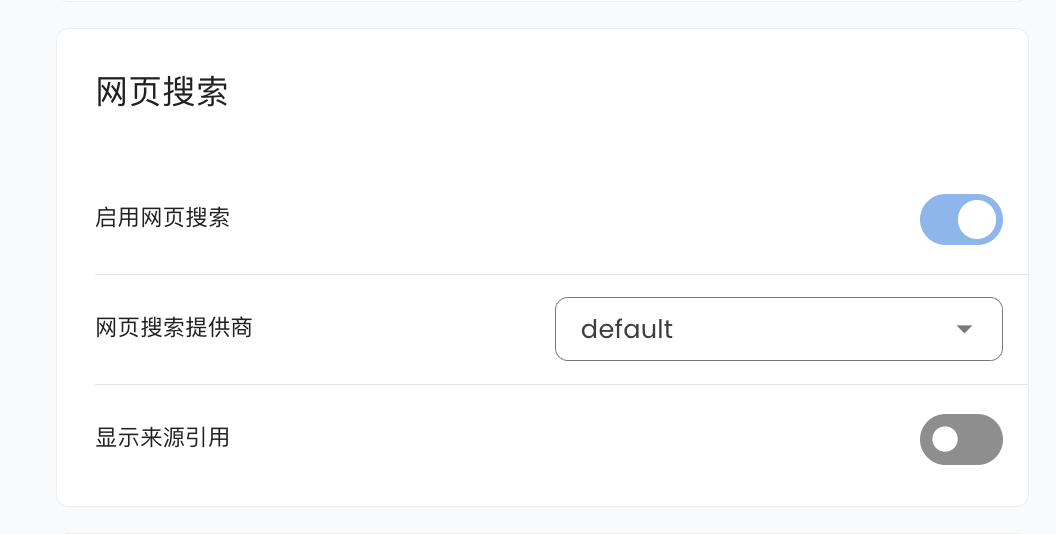
|
||||
|
||||
Go to `Configuration`, scroll down to find Web Search, where you can select `Tavily`, `BoCha`, `Baidu AI Search`, `Brave`, `Firecrawl`, or `Exa`.
|
||||
Go to `Configuration`, scroll down to find Web Search, where you can select `Tavily`, `BoCha`, `Baidu AI Search`, `Brave`, or `Firecrawl`.
|
||||
|
||||
### Tavily
|
||||
|
||||
@@ -40,10 +40,6 @@ Get an API Key from Brave Search, then fill it in the corresponding configuratio
|
||||
|
||||
Go to [Firecrawl](https://firecrawl.dev) to get an API Key, then fill it in the corresponding configuration item.
|
||||
|
||||
### Exa
|
||||
|
||||
Go to [Exa](https://dashboard.exa.ai) to get an API Key, then fill it in the corresponding configuration item. Exa is an AI-native search engine that supports keyword and semantic search with category filters, domain restrictions, and date ranges.
|
||||
|
||||
If you use Tavily as your web search source, you will get a better experience optimization on AstrBot ChatUI, including citation source display and more:
|
||||
|
||||

|
||||
|
||||
@@ -13,11 +13,11 @@ AstrBot 内置的网页搜索功能依赖大模型提供 `函数调用` 能力
|
||||
|
||||
等等带有搜索意味的提示让大模型触发调用搜索工具。
|
||||
|
||||
AstrBot 当前支持 6 种网页搜索源接入方式:`Tavily`、`BoCha`、`百度 AI 搜索`、`Brave`、`Firecrawl`、`Exa`。
|
||||
AstrBot 当前支持 5 种网页搜索源接入方式:`Tavily`、`BoCha`、`百度 AI 搜索`、`Brave`、`Firecrawl`。
|
||||
|
||||

|
||||
|
||||
进入 `配置`,下拉找到网页搜索,您可选择 `Tavily`、`BoCha`、`百度 AI 搜索`、`Brave`、`Firecrawl` 或 `Exa`。
|
||||
进入 `配置`,下拉找到网页搜索,您可选择 `Tavily`、`BoCha`、`百度 AI 搜索`、`Brave` 或 `Firecrawl`。
|
||||
|
||||
### Tavily
|
||||
|
||||
@@ -39,10 +39,6 @@ AstrBot 当前支持 6 种网页搜索源接入方式:`Tavily`、`BoCha`、`
|
||||
|
||||
前往 [Firecrawl](https://firecrawl.dev) 获取 API Key,然后填写在相应的配置项。
|
||||
|
||||
### Exa
|
||||
|
||||
前往 [Exa](https://dashboard.exa.ai) 获取 API Key,然后填写在相应的配置项。Exa 是一个 AI 原生搜索引擎,支持关键词和语义搜索,提供分类过滤、域名限制和日期范围等高级搜索功能。
|
||||
|
||||
如果您使用 Tavily 作为网页搜索源,在 AstrBot ChatUI 上将会获得更好的体验优化,包括引用来源展示等:
|
||||
|
||||

|
||||
|
||||
@@ -8,7 +8,7 @@ info:
|
||||
JSON objects because their schemas are provided at runtime by template
|
||||
endpoints.
|
||||
Developer API keys currently support these scopes only: bot, provider,
|
||||
persona, im, config, chat, data, file, plugin, mcp, skill. The config scope also
|
||||
persona, im, config, chat, file, plugin, mcp, skill. The config scope also
|
||||
grants bot and provider access.
|
||||
servers:
|
||||
- url: http://localhost:6185
|
||||
@@ -5127,8 +5127,8 @@ components:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
enum: [bot, provider, persona, im, config, chat, data, file, plugin, mcp, skill]
|
||||
example: [bot, provider, persona, im, config, chat, data, file, plugin, mcp, skill]
|
||||
enum: [bot, provider, persona, im, config, chat, file, plugin, mcp, skill]
|
||||
example: [bot, provider, persona, im, config, chat, file, plugin, mcp, skill]
|
||||
expires_at:
|
||||
type: string
|
||||
format: date-time
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[project]
|
||||
name = "AstrBot"
|
||||
version = "4.26.0-beta.12"
|
||||
version = "4.26.0-beta.11"
|
||||
description = "Easy-to-use multi-platform LLM chatbot and development framework"
|
||||
readme = "README.md"
|
||||
license = { text = "AGPL-3.0-or-later" }
|
||||
@@ -121,7 +121,7 @@ exclude = ["dashboard", "node_modules", "dist", "data", "tests"]
|
||||
allow-direct-references = true
|
||||
|
||||
# Include bundled dashboard dist even though it is not tracked by VCS.
|
||||
[tool.hatch.build]
|
||||
[tool.hatch.build.targets.wheel]
|
||||
artifacts = ["astrbot/dashboard/dist/**"]
|
||||
|
||||
# Custom build hook: builds the Vue dashboard and copies dist into the package.
|
||||
|
||||
@@ -2,15 +2,10 @@
|
||||
|
||||
from datetime import datetime, timedelta, timezone
|
||||
from unittest.mock import AsyncMock, MagicMock, patch
|
||||
from zoneinfo import ZoneInfo
|
||||
|
||||
import pytest
|
||||
|
||||
from astrbot.core.cron.manager import (
|
||||
CronJobManager,
|
||||
CronJobSchedulingError,
|
||||
_normalize_crontab_day_of_week,
|
||||
)
|
||||
from astrbot.core.cron.manager import CronJobManager, CronJobSchedulingError
|
||||
from astrbot.core.db.po import CronJob
|
||||
|
||||
|
||||
@@ -374,15 +369,6 @@ class TestRemoveScheduled:
|
||||
class TestScheduleJob:
|
||||
"""Tests for _schedule_job method."""
|
||||
|
||||
def test_normalize_crontab_day_of_week(self):
|
||||
"""Test standard crontab weekday numbers are normalized."""
|
||||
assert _normalize_crontab_day_of_week("0") == "sun"
|
||||
assert _normalize_crontab_day_of_week("7") == "sun"
|
||||
assert _normalize_crontab_day_of_week("1-5") == "mon,tue,wed,thu,fri"
|
||||
assert _normalize_crontab_day_of_week("*/2") == "sun,tue,thu,sat"
|
||||
assert _normalize_crontab_day_of_week("0-6") == "*"
|
||||
assert _normalize_crontab_day_of_week("mon-fri") == "mon-fri"
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_schedule_job_basic(
|
||||
self, cron_manager, sample_cron_job, mock_context
|
||||
@@ -397,30 +383,6 @@ class TestScheduleJob:
|
||||
# Verify job was added to scheduler
|
||||
assert cron_manager.scheduler.get_job("test-job-id") is not None
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_schedule_job_uses_standard_crontab_weekday_numbers(
|
||||
self, cron_manager, sample_cron_job, mock_context
|
||||
):
|
||||
"""Test Sunday=0 crontab jobs are scheduled for Sunday."""
|
||||
sample_cron_job.cron_expression = "0 9 * * 0"
|
||||
sample_cron_job.timezone = "Asia/Shanghai"
|
||||
mock_db = cron_manager.db
|
||||
mock_db.list_cron_jobs = AsyncMock(return_value=[])
|
||||
mock_db.update_cron_job = AsyncMock()
|
||||
|
||||
await cron_manager.start(mock_context)
|
||||
cron_manager._schedule_job(sample_cron_job)
|
||||
|
||||
aps_job = cron_manager.scheduler.get_job("test-job-id")
|
||||
assert aps_job is not None
|
||||
next_fire_time = aps_job.trigger.get_next_fire_time(
|
||||
None,
|
||||
datetime(2026, 6, 22, tzinfo=ZoneInfo("Asia/Shanghai")),
|
||||
)
|
||||
assert next_fire_time == datetime(
|
||||
2026, 6, 28, 9, 0, tzinfo=ZoneInfo("Asia/Shanghai")
|
||||
)
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_schedule_job_with_timezone(
|
||||
self, cron_manager, sample_cron_job, mock_context
|
||||
|
||||
@@ -378,138 +378,3 @@ def _context_with_provider_settings(provider_settings):
|
||||
event=SimpleNamespace(unified_msg_origin="test:private:session"),
|
||||
)
|
||||
return SimpleNamespace(context=agent_context)
|
||||
|
||||
|
||||
# --- Exa tests ---
|
||||
|
||||
|
||||
def test_normalize_legacy_web_search_config_migrates_exa_key():
|
||||
config = _FakeConfig({"provider_settings": {"websearch_exa_key": "exa-key"}})
|
||||
|
||||
tools.normalize_legacy_web_search_config(config)
|
||||
|
||||
assert config["provider_settings"]["websearch_exa_key"] == ["exa-key"]
|
||||
assert config.saved is True
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_exa_search_maps_results(monkeypatch):
|
||||
async def fake_exa_search(provider_settings, payload):
|
||||
assert provider_settings["websearch_exa_key"] == ["exa-key"]
|
||||
assert payload["query"] == "AstrBot"
|
||||
assert payload["numResults"] == 5
|
||||
return [
|
||||
tools.SearchResult(
|
||||
title="AstrBot",
|
||||
url="https://example.com",
|
||||
snippet="AI Agent Assistant",
|
||||
)
|
||||
]
|
||||
|
||||
monkeypatch.setattr(tools, "_exa_search", fake_exa_search)
|
||||
tool = tools.ExaWebSearchTool()
|
||||
context = _context_with_provider_settings({"websearch_exa_key": ["exa-key"]})
|
||||
|
||||
result = await tool.call(context, query="AstrBot", num_results=5)
|
||||
|
||||
parsed = json.loads(result)
|
||||
assert parsed["results"][0]["title"] == "AstrBot"
|
||||
assert parsed["results"][0]["url"] == "https://example.com"
|
||||
assert parsed["results"][0]["snippet"] == "AI Agent Assistant"
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_exa_search_raw_api_call(monkeypatch):
|
||||
session = _FakeFirecrawlSession(
|
||||
_FakeFirecrawlResponse(
|
||||
status=200,
|
||||
json_data={
|
||||
"results": [
|
||||
{
|
||||
"title": "AstrBot",
|
||||
"url": "https://example.com",
|
||||
"text": "AI Agent Assistant",
|
||||
}
|
||||
],
|
||||
},
|
||||
)
|
||||
)
|
||||
|
||||
def fake_client_session(*, trust_env):
|
||||
session.trust_env = trust_env
|
||||
return session
|
||||
|
||||
monkeypatch.setattr(tools.aiohttp, "ClientSession", fake_client_session)
|
||||
|
||||
results = await tools._exa_search(
|
||||
{"websearch_exa_key": ["exa-key"]},
|
||||
{"query": "AstrBot", "numResults": 10, "type": "auto"},
|
||||
)
|
||||
|
||||
assert session.posted["url"] == "https://api.exa.ai/search"
|
||||
assert session.posted["headers"]["x-api-key"] == "exa-key"
|
||||
assert results == [
|
||||
tools.SearchResult(
|
||||
title="AstrBot", url="https://example.com", snippet="AI Agent Assistant"
|
||||
)
|
||||
]
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_exa_search_raises_on_http_error(monkeypatch):
|
||||
session = _FakeFirecrawlSession(
|
||||
_FakeFirecrawlResponse(status=401, text_data="Unauthorized")
|
||||
)
|
||||
|
||||
def fake_client_session(*, trust_env):
|
||||
session.trust_env = trust_env
|
||||
return session
|
||||
|
||||
monkeypatch.setattr(tools.aiohttp, "ClientSession", fake_client_session)
|
||||
|
||||
with pytest.raises(
|
||||
Exception,
|
||||
match="Exa web search failed: Unauthorized, status: 401",
|
||||
):
|
||||
await tools._exa_search(
|
||||
{"websearch_exa_key": ["exa-key"]},
|
||||
{"query": "AstrBot"},
|
||||
)
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_exa_get_contents_returns_text(monkeypatch):
|
||||
async def fake_exa_get_contents(provider_settings, payload):
|
||||
assert provider_settings["websearch_exa_key"] == ["exa-key"]
|
||||
assert payload["ids"] == ["https://example.com"]
|
||||
return [{"url": "https://example.com", "text": "# Example Content"}]
|
||||
|
||||
monkeypatch.setattr(tools, "_exa_get_contents", fake_exa_get_contents)
|
||||
tool = tools.ExaGetContentsTool()
|
||||
context = _context_with_provider_settings({"websearch_exa_key": ["exa-key"]})
|
||||
|
||||
result = await tool.call(context, url="https://example.com")
|
||||
|
||||
assert result == "URL: https://example.com\nContent: # Example Content"
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_exa_get_contents_raises_on_http_error(monkeypatch):
|
||||
session = _FakeFirecrawlSession(
|
||||
_FakeFirecrawlResponse(status=403, text_data="Forbidden")
|
||||
)
|
||||
|
||||
def fake_client_session(*, trust_env):
|
||||
session.trust_env = trust_env
|
||||
return session
|
||||
|
||||
monkeypatch.setattr(tools.aiohttp, "ClientSession", fake_client_session)
|
||||
|
||||
with pytest.raises(
|
||||
Exception,
|
||||
match="Exa get contents failed: Forbidden, status: 403",
|
||||
):
|
||||
await tools._exa_get_contents(
|
||||
{"websearch_exa_key": ["exa-key"]},
|
||||
{"ids": ["https://example.com"]},
|
||||
)
|
||||
|
||||
Reference in New Issue
Block a user